Table of contents
Open Table of contents
图
偏心距
从一个点出发,到所有点的距离的最大值,就是这个点的偏心距。
所有点的偏心距的最小值,就是图的半径。
偏心距最小的点也就是图的中心点。
所有点的偏心距的最大值,就是图的直径。
直径的长度严格大于等于半径,小于等于两倍半径。
大于等于半径这个很好理解,同一个集合内的最大值大于等于它的最小值。
小于等于两倍半径呢?
假如图的直径是 A 到 B 的最短路径,那么假设中心点是 C,直径长度一定小于等于绕路的距离,而 ,,绕路的距离一定小于等于 2R,也就是直径小于等于绕路小于等于两倍半径。
树
树的重心
搜索
折半搜索
对于一些数据范围较小,但还没小到可以直接爆搜解决的问题,可以进行折半搜索。
比如,对于二叉树,数据范围是 ,那么普通的 DFS 复杂度是 ,这是不可接受的。我们可以先搜前 20,把搜索到的中间值存起来,然后再搜后半部分,看是否能够搜到与前半部分匹配的结果,这是典型的用空间换时间的思想。
图的连通性
强连通分量
Tarjan
有向图中,定义 dfn[i] 为其 DFS 序,low[i] 为其经过至多一条返祖边所能达到的 dfn 最小值。
为什么这样定义待会再说。
- 如果结点 u 是某个强连通分量在搜索时遇到的第一个结点,那么这个强连通分量的其它结点一定在 u 的子树里。
- 当 DFS 搜索到 v 时,如果没搜索过,那就可以接着向下搜索,回溯时更新
low[u] = min(low[u], low[v])。 - 当 DFS 搜索到 v 时,如果被搜索过,这时候进行分类讨论。如果被搜索过并且不在栈中,说明 v 在其它已经搜索过的强连通分量,所以跳过;如果在栈中,说明 v 在当前正在搜索的强连通分量,用
dfn[v]更新low[u]。 - 当遍历完所有子节点后,如果
low[u] = dfn[u],说明所有子节点通过最多一条返祖边,无法走出u的子树,所以u就是这个强连通分量的根,可以收网了。
对于第三点,为什么要用 dfn[v] 更新 low[u] 而不是用 low[v] 更新 low[u]:
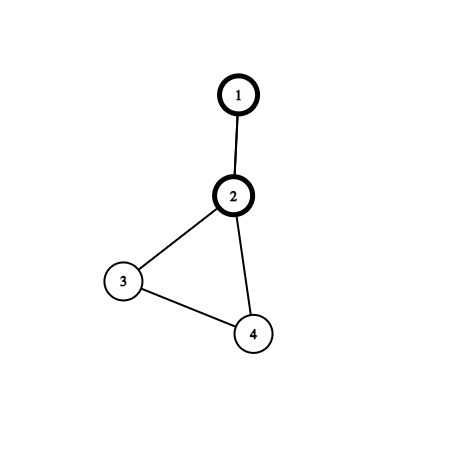
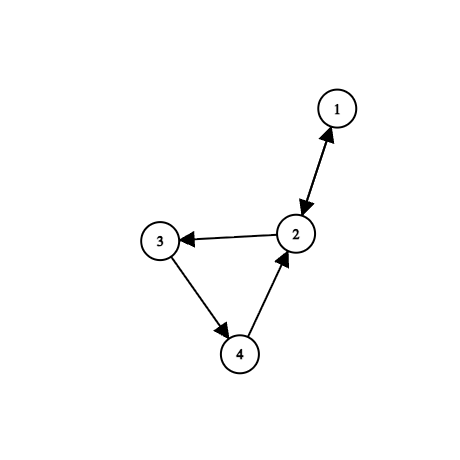
对于这样一张图,如果是有向图,low[2] = dfn[1],在 u = 4, v = 2 时,是 low[4] = low[2] 呢还是 low[4] = dfn[2]?看起来并没有什么影响,因为最后求得得强连通分量依旧是 [1, 2, 3, 4]。
但是如果是在求割点呢?割点的判断标准是 low[child] >= dfn[u],如果将 low[4] = low[2] = dfn[1] 的话,就会产生错误,因为 4 实际上是通过了两条返祖边才到达的 1,4 并不能直接到达 1,最多只能到达 2,而 2 是一个割点,所以我们就知道为什么 low 值是定义为“最多通过一条返祖边”了。
void tarjan(int u) {
dfn[u] = low[u] = ++stmp;
inStack[u] = true;
stk.push(u);
for (auto &v : e[u]) {
if (!dfn[v]) {
tarjan(v);
low[u] = min(low[u], low[v]);
} else if (inStack[v])
low[u] = min(low[u], dfn[v]);
}
if (dfn[u] == low[u]) {
cscc++;
int v;
do {
v = stk.top();
stk.pop();
scc[v] = cscc;
inStack[v] = false;
} while (u != v);
}
}Kosaraju
English 中前中后序分别是:Pre-order, In-order, Post-order
核心思想是两遍 DFS。
枚举所有的点,分别以它们为起点进行 DFS,回溯时将其加入 post_order 中,访问过则不进行遍历,这样总共加起来,这是第一次 DFS,最后加入 post_order 的点是源点。
想一想,假如图中包含互相无法到达的连通块,每个连通块的源点在
post_order中序号是否还是靠最后?
第二遍以 post_order 最后的节点为源点,在反图上进行 DFS,所有遍历到的点就是一个强连通分量。因为第一遍 DFS 保证了该点可以到达任意一点,那么只要能到达这个点(相当于反图上这个点能到达),都可以加入此强连通分量。
之后标记这些已经添加到强连通分量的点,在 post_order 中找没有标记过的序号最大的点,重复以上过程即可完成求强连通分量。
割点
在 DFS 生成树当中,非树边一定是连接某节点和它的祖先的。
如果存在横叉边,那么在 DFS 的过程中它们应该在同一颗子树,也就是祖先与后代关系。
如果节点 u 存在某子节点 v 满足:,说明 u 是一个割点。
根节点需要特殊考虑。如果只有一个子节点,那么它就不是割点,否则是。
因为非树边一定是连接祖先与后代的,所以如果根节点有多个儿子,它们之间一定没有边相连接。
代码:
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 1e5 + 7;
int n, m, stmp;
int dfn[N], low[N];
vector<int> adj[N];
vector<int> cp;
void tarjan(int u, int pa, bool first) {
bool ok = false;
int cnt = 0;
dfn[u] = low[u] = ++stmp;
for (auto v : adj[u]) {
if (v == pa) continue;
if (dfn[v])
low[u] = min(low[u], dfn[v]);
else {
cnt++;
tarjan(v, u, false);
low[u] = min(low[u], low[v]);
if (low[v] >= dfn[u] && !ok && !first) {
ok = true;
cp.emplace_back(u);
}
}
}
if (first && cnt > 1) cp.emplace_back(u);
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m;
for (int i = 0, u, v; i < m; i++) {
cin >> u >> v;
adj[u].emplace_back(v);
adj[v].emplace_back(u);
}
for (int i = 1; i <= n; i++)
if (!dfn[i]) tarjan(i, -1, true);
sort(cp.begin(), cp.end());
cout << cp.size() << '\n';
for (auto i : cp) cout << i << ' ';
return 0;
}注意:判断 时,一定要是非树边才可以。
对于这样一张图:
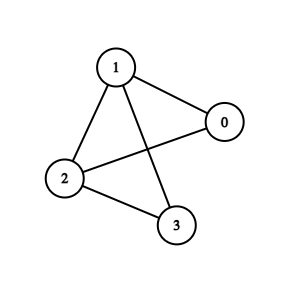
DFS 到 3 时,,然后回溯,此时 1 访问 3,发现是非树边(前向边),会错误地判断 1 为割点,而实际上 3 可以通过 2 回到 0.
所以 只能用递归过后的子节点(也就是子树所有点能回到的最小值)来进行判断。
割边(桥)
无重边时:
只需要将条件改为 即可,此时 就是一条割边。
根节点没有特殊情况。
有重边时:
重边其实是一个返祖边,不应该被当作反向边被忽略。
可以通过链式前向星,判断当前边是不是反向边。
或者判断是第几次遍历到父亲节点,如果是第一次,那么就当作是反向边,如果有第二次,那么就不可以忽略了。
点双连通分量
无论根节点是不是割点,求出来的点双连通分量都是一样的。
点双其实是一个不断将连通分量合并到割点的过程,最后无论根节点是不是割点,所有的点都会被合并到根节点,也就是最后栈内只会剩下一个根节点。
重边和自环需要特殊考虑。
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 5e5 + 7;
int n, m;
int dfn[N], low[N];
int stmp;
vector<int> adj[N];
stack<int> stk;
int cvbc;
vector<int> vbc[N];
void tarjan(int u, int pa) {
dfn[u] = low[u] = ++stmp;
if (adj[u].empty()) {
cvbc++;
vbc[cvbc].emplace_back(u);
return;
}
stk.push(u);
for (auto v : adj[u]) {
if (dfn[v]) {
low[u] = min(low[u], dfn[v]);
} else {
tarjan(v, u);
low[u] = min(low[u], low[v]);
if (low[v] >= dfn[u]) {
cvbc++;
int t;
do {
t = stk.top();
stk.pop();
vbc[cvbc].emplace_back(t);
} while (t != v);
vbc[cvbc].emplace_back(u);
}
}
}
if (pa == -1)
while (stk.size()) stk.pop();
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m;
for (int i = 0, u, v; i < m; i++) {
cin >> u >> v;
if (u == v) continue;
adj[u].emplace_back(v);
adj[v].emplace_back(u);
}
for (int i = 1; i <= n; i++) {
if (!dfn[i]) {
tarjan(i, -1);
while (stk.size()) stk.pop();
}
}
cout << cvbc << '\n';
for (int i = 1; i <= cvbc; i++) {
cout << vbc[i].size() << ' ';
for (auto v : vbc[i]) {
cout << v << ' ';
}
cout << '\n';
}
return 0;
}- 弹栈仅弹到
v - 如果没有重边,其实不需要判断
v == pa - 到最后只会剩下一个根节点。
边双连通分量
仅做了一些修改,以及判断重边。
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 5e5 + 7;
int n, m;
int dfn[N], low[N];
int stmp;
vector<int> adj[N];
stack<int> stk;
int cvbc;
vector<int> vbc[N];
void tarjan(int u, int pa) {
dfn[u] = low[u] = ++stmp;
int cnt = 0;
stk.push(u);
for (auto v : adj[u]) {
if (v == pa && !cnt) {
cnt++;
continue;
}
if (dfn[v]) {
low[u] = min(low[u], dfn[v]);
} else {
tarjan(v, u);
low[u] = min(low[u], low[v]);
if (low[v] > dfn[u]) {
cvbc++;
int t;
do {
t = stk.top();
stk.pop();
vbc[cvbc].emplace_back(t);
} while (t != v);
}
}
}
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m;
for (int i = 0, u, v; i < m; i++) {
cin >> u >> v;
if (u == v) continue;
adj[u].emplace_back(v);
adj[v].emplace_back(u);
}
for (int i = 1; i <= n; i++) {
if (!dfn[i]) {
tarjan(i, -1);
if (stk.size()) {
cvbc++;
while (stk.size()) {
vbc[cvbc].emplace_back(stk.top());
stk.pop();
}
}
}
}
cout << cvbc << '\n';
for (int i = 1; i <= cvbc; i++) {
cout << vbc[i].size() << ' ';
for (auto v : vbc[i]) {
cout << v << ' ';
}
cout << '\n';
}
return 0;
}缩点
强连通分量的缩点:
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 1e5 + 7;
int n, m;
int dfn[N], low[N], stmp, cscc, ans;
int vis[N], rd[N], f[N], w[N], W[N], c[N];
bool inS[N];
vector<int> scc[N];
stack<int> stk;
vector<int> adj[N], G[N];
void tarjan(int u) {
dfn[u] = low[u] = ++stmp;
stk.push(u);
inS[u] = true;
for (auto v : adj[u]) {
if (!dfn[v]) {
tarjan(v);
low[u] = min(low[u], low[v]);
} else if (inS[v])
low[u] = min(low[u], dfn[v]);
}
if (low[u] == dfn[u]) {
cscc++;
int t;
do {
t = stk.top();
inS[t] = false;
stk.pop();
c[t] = cscc;
scc[cscc].emplace_back(t);
} while (t != u);
}
}
void topsort() {
queue<int> q;
for (int i = 1; i <= cscc; i++) {
f[i] = W[i];
if (!rd[i]) q.push(i);
}
while (!q.empty()) {
auto t = q.front();
ans = max(ans, f[t]);
q.pop();
for (auto v : G[t]) {
f[v] = max(f[v], f[t] + W[v]);
rd[v]--;
if (!rd[v]) {
q.push(v);
}
}
}
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m;
for (int i = 1; i <= n; i++) {
cin >> w[i];
}
for (int i = 0, u, v; i < m; i++) {
cin >> u >> v;
adj[u].emplace_back(v);
}
for (int i = 1; i <= n; i++) {
if (!dfn[i]) tarjan(i);
}
for (int i = 1; i <= cscc; i++) {
for (auto u : scc[i]) {
W[i] += w[u];
for (auto v : adj[u]) {
if (c[u] != c[v] && vis[c[v]] != c[u]) {
vis[c[v]] = c[u];
rd[c[v]]++;
G[c[u]].emplace_back(c[v]);
}
}
}
}
topsort();
cout << ans << '\n';
return 0;
}- 去重边:
vis[v] = u代表 u 到 v 有一条连边,由于我们是按顺序枚举的,所以vis[v]不会被错误更新,可以很好地判断重边。
而对于无向图中的缩点,对于点双连通分量的缩点,见圆方树。
对于边双连通分量的缩点,与强连通分量类似,不过不需要去重边,因为两个不同的边双连通分量之间不可能出现两条不同的边,不然它们就会是同一个连通分量。
圆方树
在求点双连通分量的过程中,我们发现每个割点都属于不同的点双连通分量。那怎么缩点呢?
我们可以为每个点双连通分量建一个虚拟点,该点连接所有点双连通分量内的点,这样建出来的图是一颗树。
原图的点记为圆点,虚拟点记为方点。
- 圆方树为一个二分图,因为圆点只和方点连边。
- 圆方树上度数大于一的圆点是割点。
为什么一定是一颗树?
由于是二分图,假设有环,那么一定是方点圆点交替出现,这时候每个圆点都是一个割点,但实际上去掉任意一个“割点”都不会导致连通分量的增加,矛盾,这个环将合成为一个连通分量。
圆方树可以解决什么样的问题?
- 假如有一个稠密的无向图,求两点间所有简单路径节点的最小值。
两点间的简单路径条数是指数级的。
我们就可以用圆方树将其转换为一个树上问题,方点的权值就是它连接的所有圆点的权值最小值,因为进入到一个点双后,怎么走都可以,一定有走到该最小值的方案。
- 假如还是一个稠密的无向图,问去掉一个节点,让两点无法连通的节点个数。
在圆方树上,简单路径是圆点和方点交替排布的,每个圆点都是一个割点,统计圆点个数即可。
- 回到第一问,如果需要动态修改节点的值,可以使用
multiset维护方点内所有的点。
二分图
一个图可以被划分为两个点集,这两个点集内部没有边,所有边的两个端点属于不同的点集,即二分图。
可以用染色法进行求解,给当前点 染色为 ,给 染色为 ,如果遇到一个点已经染色过并且颜色相同,则不是二分图,否则继续遍历。
二分图一定没有奇数大小的环。(如果有,颜色交替下,最终都会出现相邻的同色节点,所以不符合条件)
树、网格图是常见的二分图。
最大匹配
给你一个二分图,每个点只能与一个节点通过一条边相连(匹配),问最多有多少对这样的匹配?
Kuhn
匈牙利算法的一部分,用于求最大匹配。
增广路径:起始点和终点都是未匹配的点,路径满足匹配的边和未匹配的边严格交替出现,此时反转所有的匹配关系,就可以让匹配数加一。
算法就是一个寻找增广路径的过程。
LCA
倍增 LCA
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 5e5 + 7;
vector<int> adj[N];
int depth[N];
int f[N][30];
int n, m, s;
void dfs(int u) {
for (auto &v : adj[u]) {
if (v == f[u][0])
continue;
f[v][0] = u;
depth[v] = depth[u] + 1;
for (int j = 1; (1 << j) <= n; j++) {
f[v][j] = f[f[v][j - 1]][j - 1];
}
dfs(v);
}
}
int lca(int u, int v) {
if (depth[u] < depth[v]) {
swap(u, v);
}
for (int i = 29; i >= 0; i--) {
if (depth[f[u][i]] >= depth[v])
u = f[u][i];
}
if (u == v)
return u;
for (int i = 29; i >= 0; i--) {
if (f[u][i] != f[v][i]) {
u = f[u][i];
v = f[v][i];
}
}
return f[u][0];
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1; i < n; i++) {
int u, v;
cin >> u >> v;
if (u == v)
continue;
adj[u].emplace_back(v);
adj[v].emplace_back(u);
}
depth[0] = -1; // *
dfs(s);
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
cout << lca(u, v) << endl;
}
return 0;
}注意事项:
- 有
f[u][0]记录父亲了,所以 DFS 不需要多一个参数 - 由于是这样边递归边预处理(因为祖先们都处理过了,所以可以这样做),所以根节点是没有处理过的,于是所有超界的节点都变成了 0(全局变量初始值),在调整深度时,假设
v是根节点,深度是 0,要把u也调整到深度为 0,此时就会错误地跳到这个不存在的零号节点上。为了解决这个问题,把零号节点的深度设置为 -1 或者把根节点的深度设置为 1。 - 刚进函数时需要判断两个点是否相同,调整完深度后也需要判断,方便起见这里只在调整深度后判断一次。
欧拉序 LCA
欧拉序:遍历和回溯时都会新增一个时间戳,那么 的 LCA 的欧拉序一定在 的欧拉序区间内。
RMQ 问题。
DFS 序 LCA
欧拉序的优化版,原文:Link
如果是 DFS 序的话,LCA 将不在区间内,但是它的某一个子节点一定在,所以如果 LCA 不是 u, v 其中某一点的话,那么答案就是 DFS 序最小的点的父亲。
如果 LCA 是 u 的话,怎么办?
我们可以把查询区间修改为:
在具体实现上,我们直接在 ST 表底层填入父亲,这样就避免了存储父亲。
比 LCA 快一倍。
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 5e5 + 7;
int n, m, s;
vector<int> adj[N];
int dfn[N], dn;
int st[25][N];
int lg[N];
void dfs(int u, int pa) {
dfn[u] = ++dn;
st[0][dn] = pa;
for (auto &v : adj[u])
if (v != pa)
dfs(v, u);
}
int get(int u, int v) { return dfn[u] < dfn[v] ? u : v; }
int lca(int u, int v) {
if (u == v)
return u;
u = dfn[u], v = dfn[v];
if (u > v)
swap(u, v);
u++;
int k = lg[v - u + 1];
return get(st[k][u], st[k][v - (1 << k) + 1]);
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1, u, v; i < n; i++) {
cin >> u >> v;
adj[u].emplace_back(v);
adj[v].emplace_back(u);
}
dfs(s, 0);
lg[1] = 0;
for (int i = 2; i <= n; i++) {
lg[i] = lg[i >> 1] + 1;
}
for (int i = 1; i <= lg[n]; i++) {
for (int j = 1; j + (1 << i) - 1 <= n; j++) {
st[i][j] = get(st[i - 1][j], st[i - 1][j + (1 << (i - 1))]);
}
}
for (int i = 0, u, v; i < m; i++) {
cin >> u >> v;
cout << lca(u, v) << '\n';
}
return 0;
}最短路
Bellman-Ford
暴力枚举每一条边,每次尝试用这条边进行松弛操作。
每次至少松弛一次,最短路一共有 n - 1 条边,所以最多松弛 n - 1 次。
如果第 次依旧有松弛操作,那么就说明有负环。
注:松弛前需要判断该点是否可达(存在负边权的情况下会错误松弛
参考实现:Bellman-Ford
复杂度
SPFA
最短路一定是通过其它最短路得来的。
所以我们维护一个队列,记录松弛过的点,下次只考虑它们的出边,这些点可能会引起松弛操作。
一个点可能会被松弛很多次,所以复杂度可以被卡为 Bellman-Ford。
可以通过记录最短路经过的边数来判断负环。
差分约束
Dijkstra
出堆时,该点的最短路确定。
可以用 vis 数组记录每个点是否被松弛过,如果 vis[u] = true,则不再进行松弛。
也可以直接用 dist[u] < d 来判断,u 已经被松弛过了,那么它的 dist 值已经作为最小值停止更新。
堆优化的复杂度 ,,在稠密图中复杂度不如暴力复杂度
Floyd
多源最短路
代表只允许经过中间点 ,的最短路径。
初始 f[0][i][j] 就是边权。无边是负无穷,自己到自己是 0。
for (int k = 1; k <= n; k++)
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++) {
f[k][i][j] = min(f[k - 1][i][j], f[k - 1][i][k] + f[k - 1][k][j]);
}然后我们发现在这个 DP 过程中,每个 (i, j), (i, k), (k, j) 都不会重复更新,也就是说第一维数组实际上可以优化掉。
每次 f[i][k] = min(f[i][k], f[i][k] + f[k][k]) 也就是没有得到更新,所以拿它更新其它的 [i][j] 不会出现重复转移的问题,实际上就是新加了一条 i, k 的边,排着更新。
k, j 同理。
无向图,找一个最小的环?
最小的环其实就是由 f[i][j] 和环内编号最大的 k 组成。
所以最小环其实就是:f[k - 1][i][j] + f[k][i][k] + f[k][k][j],每次循环更新即可。
判断图任意两点的连通性
for (int k = 1; k <= n; k++)
for (int i = 1; i <= n; i++) {
if (f[i][k]) f[i] |= f[k];
// f[i][j] = f[i][j] | (f[i][k] & f[k][j]);
}使用 bitset 可以优化 64 倍常数,因为计算机单次运算是可以解决 64 位的数字(对于 64 位计算机)。
Johnson
跑 n 遍 Bellman-Ford 的复杂度是
跑 n 遍 Dijkstra 的复杂度是
但是如果有负边权呢?
先创建一个虚拟源点,让它对每个点连一条边权为 0 的边,然后跑 Bellman-Ford,得到 。
(实际上大部分与负边权无关的点, 值为 0)
如何保证 边权非负呢?
对于一条边 ,通过三角不等式可以得到:,移项得到:。
于是可以先对每条边 的边权 ,然后跑 Dijkstra。
求出 的最短路就是
最终答案是 。
标记
在 Dijkstra 中,我们发现是在出堆时进行标记。而在 BFS 求层数时,是在入队时就进行标记,两者有什么区别,又为什么要这样做?
标记的目的是为了让这个值不再被更新,表示这个值已经是最优值了。
在 Dijkstra 中,出堆时,代表它的最短路已经被确定了。而在 BFS 中,入队时,它的最短路就已经被修改并确定了,为了防止后面被其它遍历到的点再次修改,所以在入队时(前)就要打上标记。
对于 SPFA 来说,标记仅代表这个点已经在队列里了,无需重复添加,出队时要记得清楚标记。
最小生成树
Kruscal
按照边权排序,从小到大枚举,如果这条边的两个点不在同一个集合,那么就将这条边加入到最小生成树中。
用并查集维护,排序复杂度 ,并查集复杂度 。
P1195
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
int n, m, k;
struct Edge {
int u, v, w;
bool operator<(const Edge &a) const { return w < a.w; }
};
struct DSU {
vector<int> pa, siz;
void init(int n) {
pa.resize(n), siz.assign(n, 1);
iota(pa.begin(), pa.end(), 0);
}
int find(int x) { return pa[x] == x ? x : pa[x] = find(pa[x]); }
void unite(int x, int y) {
x = find(x), y = find(y);
if (x == y)
return;
if (siz[x] < siz[y])
swap(x, y);
pa[y] = x;
siz[x] += siz[y];
}
} dsu;
vector<Edge> e;
vector<bool> inT;
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> k;
e.resize(m);
dsu.init(n + 1);
inT.resize(m);
for (int i = 0; i < m; i++) {
cin >> e[i].u >> e[i].v >> e[i].w;
}
sort(e.begin(), e.end());
int cnt = 0;
ll sum = 0;
for (int i = 0; i < m; i++) {
if (dsu.find(e[i].u) != dsu.find(e[i].v)) {
dsu.unite(e[i].u, e[i].v);
cnt++;
inT[i] = true;
sum += e[i].w;
}
}
if (k < n - cnt || k > n) {
cout << "No Answer" << '\n';
return 0;
}
k -= (n - cnt);
for (int i = m - 1; ~i && k; i--) {
if (inT[i]) {
sum -= e[i].w;
k--;
}
}
cout << sum << '\n';
return 0;
}P1967 货车运输
先求最大生成树,然后倍增求路径最小值即可。
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 1e4 + 7;
#define fi first
#define se second
using pii = pair<int, int>;
using pli = pair<ll, int>;
using pil = pair<int, ll>;
using pll = pair<ll, ll>;
const int INF = 1e9;
struct Node {
int u, v, w;
Node(int u, int v, int w) : u(u), v(v), w(w) {}
bool operator<(const Node &a) const { return w > a.w; }
};
struct DSU {
vector<int> pa, siz;
void init(int n) {
pa.resize(n), siz.assign(n, 1);
iota(pa.begin(), pa.end(), 0);
}
void unite(int x, int y) {
x = find(x);
y = find(y);
if (x == y)
return;
if (siz[x] < siz[y])
swap(x, y);
siz[x] += siz[y];
pa[y] = x;
}
int find(int u) { return u == pa[u] ? u : pa[u] = find(pa[u]); }
} dsu;
vector<pii> adj[N];
bool vis[N];
vector<Node> edge;
int f[25][N];
int dep[N];
int min_val[25][N];
void dfs(int u, int pa) {
vis[u] = true;
dep[u] = dep[pa] + 1;
for (auto [v, w] : adj[u]) {
if (v == pa)
continue;
f[0][v] = u;
min_val[0][v] = w;
for (int i = 1; i <= 20; i++) {
f[i][v] = f[i - 1][f[i - 1][v]];
min_val[i][v] = min(min_val[i - 1][v], min_val[i - 1][f[i - 1][v]]);
}
dfs(v, u);
}
}
int query(int x, int y) {
if (dsu.find(x) != dsu.find(y))
return -1;
if (dep[x] < dep[y])
swap(x, y);
int res = INF;
for (int i = 20; ~i; i--) {
if (dep[f[i][x]] >= dep[y]) {
res = min(res, min_val[i][x]);
x = f[i][x];
}
}
if (x == y)
return res;
for (int i = 20; ~i; i--) {
if (f[i][x] != f[i][y]) {
res = min(res, min(min_val[i][x], min_val[i][y]));
x = f[i][x];
y = f[i][y];
}
}
return min(res, min(min_val[0][x], min_val[0][y]));
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int n, m, q;
cin >> n >> m;
dsu.init(n + 1);
for (int i = 0, u, v, w; i < m; i++) {
cin >> u >> v >> w;
edge.emplace_back(u, v, w);
}
sort(edge.begin(), edge.end());
for (auto [u, v, w] : edge) {
if (dsu.find(u) != dsu.find(v)) {
dsu.unite(u, v);
adj[u].emplace_back(v, w);
adj[v].emplace_back(u, w);
}
}
memset(min_val, 0x3f, sizeof(min_val));
for (int i = 1; i <= n; i++) {
if (!vis[i])
dfs(i, 0);
}
cin >> q;
while (q--) {
int x, y;
cin >> x >> y;
cout << query(x, y) << '\n';
}
return 0;
}Prim
从一个点开始,把所有边加入到考虑集合,然后从这个边集中选择最小的一条边,把新点连着的、未访问过的所有边加入到集合中,重复过程。
类似 Dijktra
堆优化的复杂度为:/
次小生成树
严格次小生成树
维护最大值和次大值的倍增表即可。
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 7;
using ll = long long;
#define fi first
#define se second
using pii = pair<int, int>;
using pli = pair<ll, int>;
using pil = pair<int, ll>;
using pll = pair<ll, ll>;
struct Edge {
int u, v, w;
Edge(int u, int v, int w) : u(u), v(v), w(w) {}
bool operator<(const Edge &a) const { return w < a.w; }
};
struct DSU {
vector<int> pa, siz;
void init(int n) {
pa.resize(n), siz.assign(n, 1);
iota(pa.begin(), pa.end(), 0);
}
void unite(int x, int y) {
x = find(x), y = find(y);
if (x == y)
return;
if (siz[x] < siz[y])
swap(x, y);
siz[x] += siz[y];
pa[y] = x;
}
int find(int x) { return x == pa[x] ? x : pa[x] = find(pa[x]); }
} dsu;
vector<vector<pii>> adj;
int dep[N];
int f[25][N];
int max_v[25][N];
int max_vv[25][N];
void dfs(int u, int pa) {
dep[u] = dep[pa] + 1;
for (auto [v, w] : adj[u]) {
if (v == pa)
continue;
f[0][v] = u;
max_v[0][v] = w;
max_vv[0][v] = -1;
for (int i = 1; i <= 20; i++) {
f[i][v] = f[i - 1][f[i - 1][v]];
int a = max_v[i - 1][v], b = max_vv[i - 1][v];
int c = max_v[i - 1][f[i - 1][v]], d = max_vv[i - 1][f[i - 1][v]];
max_v[i][v] = max(a, c);
max_vv[i][v] = max(b, d);
if (a != max_v[i][v])
max_vv[i][v] = max(max_vv[i][v], a);
if (c != max_v[i][v])
max_vv[i][v] = max(max_vv[i][v], c);
}
dfs(v, u);
}
}
int query(int x, int y, int w) {
int res = -1;
auto update = [&](int val1, int val2) {
if (val1 < w)
res = max(res, val1);
if (val2 < w)
res = max(res, val2);
};
if (dep[x] < dep[y])
swap(x, y);
for (int i = 20; ~i; i--) {
if (dep[f[i][x]] >= dep[y]) {
update(max_v[i][x], max_vv[i][x]);
x = f[i][x];
}
}
if (x == y)
return res;
for (int i = 20; ~i; i--) {
if (f[i][x] != f[i][y]) {
update(max_v[i][x], max_vv[i][x]);
update(max_v[i][y], max_vv[i][y]);
x = f[i][x], y = f[i][y];
}
}
update(max_v[0][x], max_v[0][y]);
return res;
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int n, m;
cin >> n >> m;
dsu.init(n + 1);
adj.resize(n + 1);
vector<Edge> e;
for (int i = 0, u, v, w; i < m; i++) {
cin >> u >> v >> w;
e.emplace_back(u, v, w);
}
sort(e.begin(), e.end());
vector<bool> inT(e.size());
ll sum = 0;
for (int i = 0; i < e.size(); i++) {
auto [u, v, w] = e[i];
if (dsu.find(u) != dsu.find(v)) {
dsu.unite(u, v);
sum += w;
adj[u].emplace_back(v, w);
adj[v].emplace_back(u, w);
inT[i] = true;
}
}
memset(max_v, -1, sizeof(max_v));
memset(max_vv, -1, sizeof(max_vv));
dfs(1, 0);
ll ans = 1e18;
for (int i = 0; i < e.size(); i++)
if (!inT[i]) {
auto [u, v, w] = e[i];
int t = query(u, v, w);
if (t == -1)
continue;
ans = min(ans, sum - t + w);
}
cout << ans << endl;
return 0;
}欧拉图
欧拉路径/欧拉回路
无向图:
- 欧拉回路:图连通,且所有顶点度数均为偶数
- 欧拉路径:图连通,且恰好有 0 或 2 个奇度数顶点(2个时,这两个点是起终点)
有向图:
- 欧拉回路:图弱连通,且每个顶点入度 = 出度
- 欧拉路径:图弱连通,且至多一个顶点出度 − 入度 = 1(起点),至多一个顶点入度 − 出度 = 1(终点),其余顶点入度 = 出度
从起点出发 DFS,在回溯时记录路径,倒序输出。
例题:
P2731 [USACO3.3] 骑马修栅栏 Riding the Fences
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 507;
int d[N];
vector<int> adj[N];
map<pair<int, int>, int> vis;
vector<int> path;
void dfs(int u) {
for (auto &v : adj[u]) {
if (vis[{u, v}] <= 0)
continue;
vis[{u, v}]--, vis[{v, u}]--;
dfs(v);
}
path.emplace_back(u);
}
int s, t;
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int m;
cin >> m;
for (int i = 0, u, v; i < m; i++) {
cin >> u >> v;
adj[u].emplace_back(v), adj[v].emplace_back(u);
vis[{u, v}]++, vis[{v, u}]++;
d[u]++, d[v]++;
}
for (int i = 1; i <= 500; i++) {
sort(adj[i].begin(), adj[i].end());
if (!d[i])
continue;
if (d[i] & 1) {
if (s)
t = i;
else
s = i;
}
}
if (!s && !t) {
for (int i = 1; i <= 500; i++)
if (d[i]) {
s = i;
break;
}
}
dfs(s);
reverse(path.begin(), path.end());
for (auto i : path)
cout << i << '\n';
return 0;
}树链剖分
重链剖分:
- 重儿子:子树最大的儿子。
- 重链:重儿子组成的链,或者只有一个点(轻儿子)。
- 链顶:重链中深度最浅的点。
一棵树中任意一条路径都可以被拆分为 个重链。
而在以重儿子优先 DFS 的 DFS 序中,我们发现任意一条重链,DFS 序都是连续的:
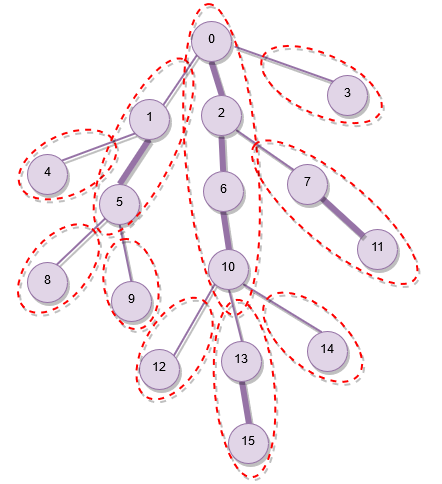
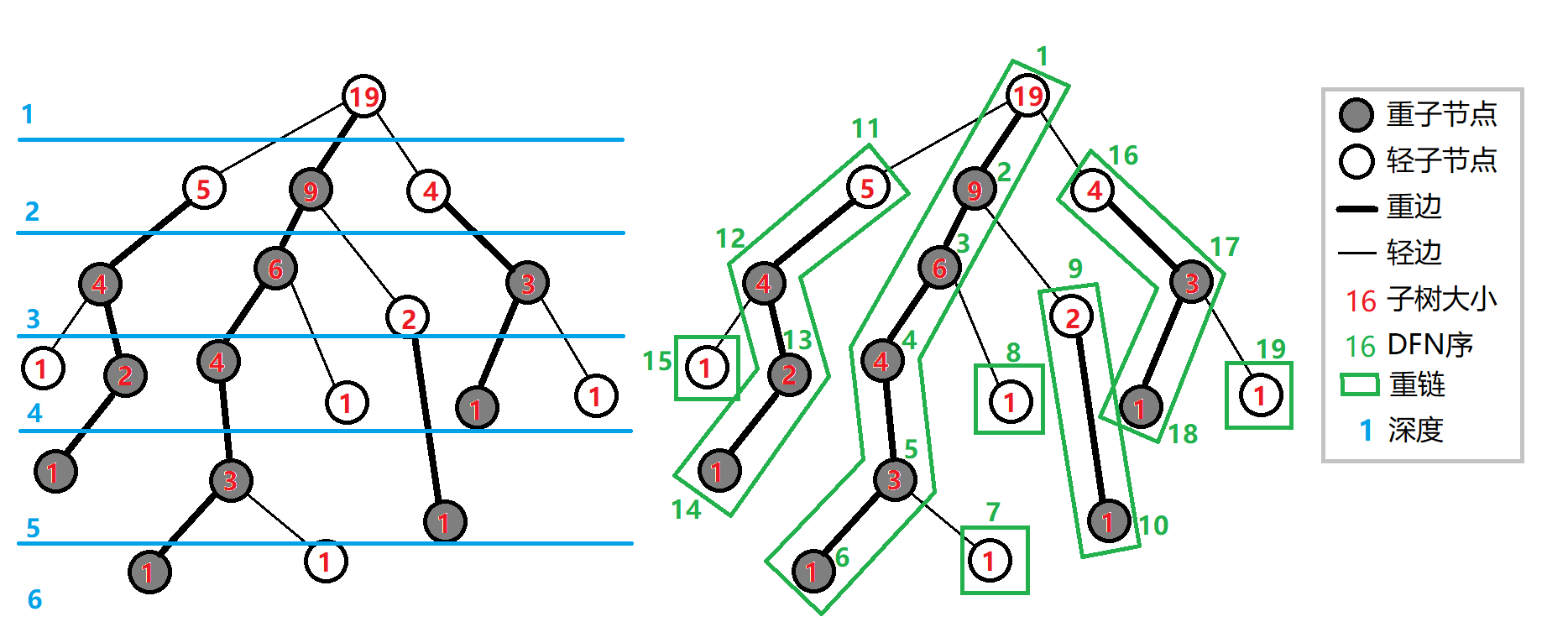
因此我们可以通过树链剖分将树上操作转换为区间操作。
维护区间操作常用的数据结构可以使用线段树,下面附上模板题代码:
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 1e5 + 7;
int n, m, root;
ll P;
int a[N], fa[N], sz[N], dep[N], son[N], top[N], id[N], w[N];
int idx = 0;
vector<int> adj[N];
class SegmentT {
struct Node {
int l, r;
ll sum, tag;
} tr[N << 2];
void pushup(int u) { tr[u].sum = (tr[u << 1].sum + tr[u << 1 | 1].sum) % P; }
void pushdown(int u) {
Node &L = tr[u << 1], &R = tr[u << 1 | 1], &Ro = tr[u];
if (Ro.tag) {
L.sum += 1ll * (L.r - L.l + 1) * Ro.tag % P;
R.sum += 1ll * (R.r - R.l + 1) * Ro.tag % P;
L.tag += Ro.tag % P;
R.tag += Ro.tag % P;
Ro.tag = 0;
}
}
public:
void build(int u, int l, int r) {
tr[u].l = l, tr[u].r = r;
if (l == r) {
tr[u].sum = w[l];
tr[u].tag = 0;
return;
}
int mid = (l + r) >> 1;
build(u << 1, l, mid), build(u << 1 | 1, mid + 1, r);
pushup(u);
}
void modify(int u, int l, int r, int x) {
if (l <= tr[u].l && tr[u].r <= r) {
tr[u].sum += (tr[u].r - tr[u].l + 1) * x % P;
tr[u].tag += x % P;
return;
}
pushdown(u);
int mid = (tr[u].l + tr[u].r) >> 1;
if (l <= mid) modify(u << 1, l, r, x);
if (r > mid) modify(u << 1 | 1, l, r, x);
pushup(u);
}
ll query(int u, int l, int r) {
if (l <= tr[u].l && tr[u].r <= r) {
return tr[u].sum;
}
pushdown(u);
ll res = 0;
int mid = (tr[u].l + tr[u].r) >> 1;
if (l <= mid) res = (res + query(u << 1, l, r)) % P;
if (r > mid) res = (res + query(u << 1 | 1, l, r)) % P;
return res;
}
} T;
void dfs1(int u, int pa, int d) {
sz[u] = 1;
son[u] = 0;
dep[u] = d;
fa[u] = pa;
for (auto v : adj[u]) {
if (v == pa) continue;
dfs1(v, u, d + 1);
sz[u] += sz[v];
if (sz[v] > sz[son[u]]) son[u] = v;
}
}
void dfs2(int u, int t) {
id[u] = ++idx;
w[idx] = a[u];
top[u] = t;
if (!son[u]) return;
dfs2(son[u], t);
for (auto v : adj[u]) {
if (v == fa[u] || v == son[u]) continue;
dfs2(v, v);
}
}
ll query_t(int u, int v) {
ll res = 0;
while (top[u] != top[v]) {
if (dep[top[u]] < dep[top[v]]) swap(u, v);
res = (res + T.query(1, id[top[u]], id[u])) % P;
u = fa[top[u]];
}
if (dep[u] > dep[v]) swap(u, v);
res = (res + T.query(1, id[u], id[v])) % P;
return res;
}
void add(int u, int v, int x) {
while (top[u] != top[v]) {
if (dep[top[u]] < dep[top[v]]) swap(u, v);
T.modify(1, id[top[u]], id[u], x);
u = fa[top[u]];
}
if (dep[u] > dep[v]) swap(u, v);
T.modify(1, id[u], id[v], x);
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> root >> P;
for (int i = 1; i <= n; i++) {
cin >> a[i];
a[i] %= P;
}
for (int i = 0, u, v; i < n - 1; i++) {
cin >> u >> v;
adj[u].emplace_back(v);
adj[v].emplace_back(u);
}
dfs1(root, -1, 1);
dfs2(root, root);
T.build(1, 1, n);
int opt, x, y, z;
while (m--) {
cin >> opt;
switch (opt) {
case 1:
cin >> x >> y >> z;
add(x, y, z);
break;
case 2:
cin >> x >> y;
cout << query_t(x, y) << '\n';
break;
case 3:
cin >> x >> z;
T.modify(1, id[x], id[x] + sz[x] - 1, z);
break;
case 4:
cin >> x;
cout << T.query(1, id[x], id[x] + sz[x] - 1) << '\n';
break;
}
}
return 0;
}查询思路:如果两个点不是在同一条重链上,则观察各自所在的重链头,深度较深的向上跳一个重链,如此循环,直到两者在同一条重链上。
几个注意事项:
v == fa[u] || v == son[u]- 下标偏移
- 线段树的查询
mid = (tr[u].l + tr[u].r) >> 1